Non je ne parle pas de voiture ici !
En ce début d’année 2025, comme à chaque début d’année, on présente ses voeux, ce que je m’empresse de faire au nom de toute l’équipe d’Implcit. Merci pour votre fidélité, et pour les projets excitants qui nous attendent !
En début d’année, il est aussi de bon ton de s’aventurer à un peu de prospective. Je n’y dérogerai pas, mais sans prendre le moindre risque cette fois.
Quand je parle d’hybridation, je fais référence à la combinaison de deux sources de données pour construire une troisième source qui prend le meilleur des deux. En l’occurrence, les deux sources peuvent être définies ainsi :
| Data déterministes | Données statistiques |
|---|---|
| Hyper granulaires | Agrégées |
| Parfois considérées comme certaines | Probabilistes (et assumées comme telles) |
| Fondées sur des identifiants | Sans identifiants |
| AKA first party ou third party (le second party a été cassé 😉) | AKA zero party |
| Nécessitent un consentement | Pas besoin de consentement |
| Partielles (besoin d’identifiant ET de consentement) | Exhaustives (projection) |
| Ces caractéristiques regroupent les cookies tiers, les identifiants (universels ou probabilistes), les data des cartes de fidélité, etc. | Les données statistiques vont du MMM pour les plus agrégées, aux sondages, et aux panels mesurés pour les plus granulaires. |
La distinction « data » vs « données » insiste sur la notion de « data utilisateurs » souvent résumées à « data » dans le monde publicitaire. Les « données », elles, correspondent à des informations, non reliées à des individus.
Quand j’écris « le meilleur des deux », je fais référence à deux objectifs fondamentaux de la publicité digitale :
- la précision, la granularité…
- le volume, la couverture…
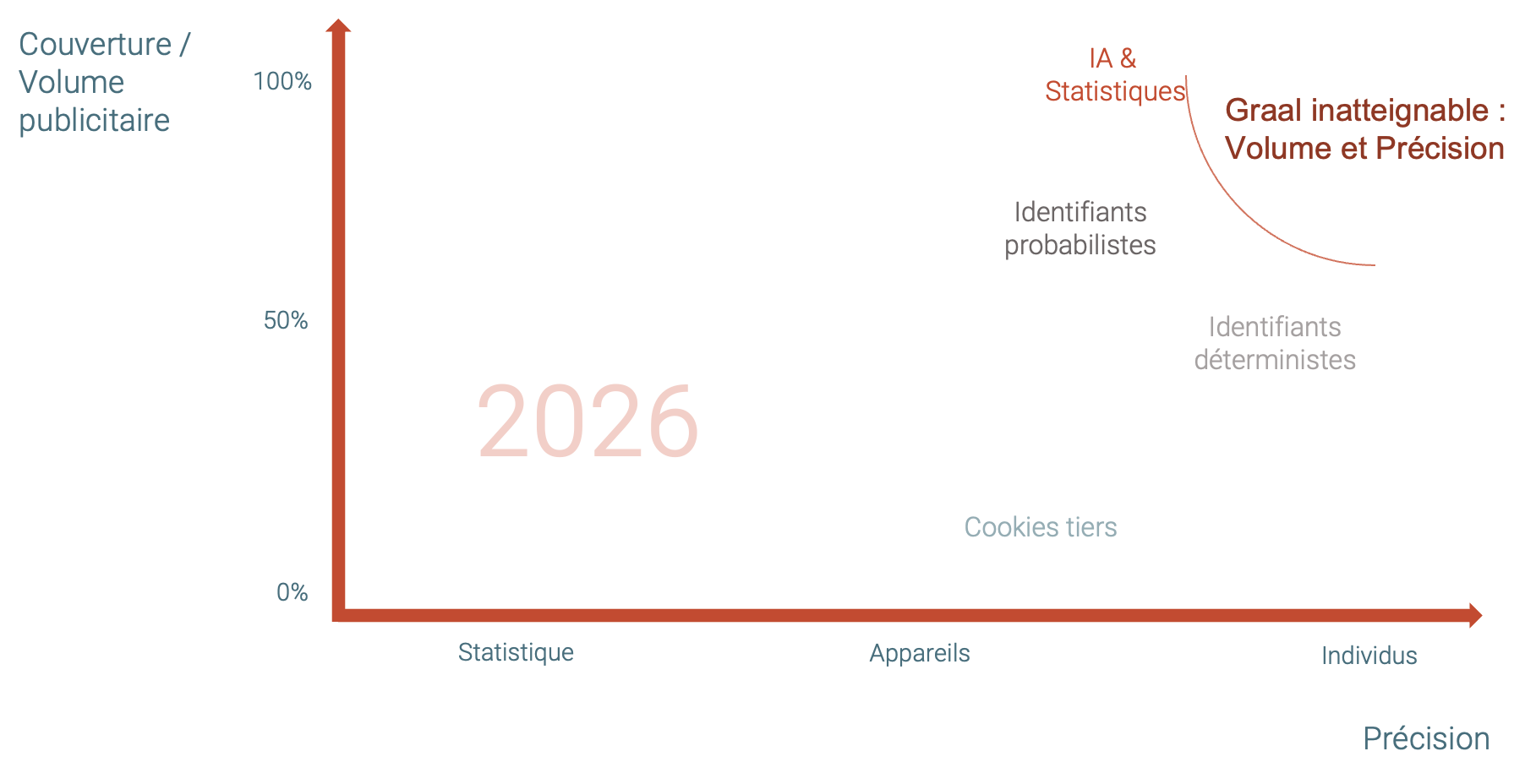
Ces deux objectifs sont difficiles, voire impossible, à concilier. Le Graal d’un système précis et complet reste un mythe. Comme à Galahad, seule la quête du Graal nous est ouverte, il restera introuvable. C’est vers ce Graal que tendent toutes les technologies publicitaires depuis des années.
L’animation ci-dessous présente l’évolution de différentes technologies publicitaires depuis 2018, ou plus précisément depuis le 19 mai 2018 :
- Les cookies tiers règnent en maîtres (mais pâtissent d’une qualité de données limitée), les identifiants déterministes balbutient, les données statistiques sont imprécises.
- 20 mai 2018, le RGPD entre en action. Tous les systèmes d’identifiants et les cookies sont soumis au consentement.
- 2019-2020, les cookies tiers disparaissent de certains navigateurs. Avec les mobiles, les appareils deviennent de plus en plus personnels, et leurs données s’individualisent.
- En 2024, les données statistiques restent à 100% de couverture, et leur précision rivalise avec les data déterministes.
- En 2026 (enfin, disons, un jour), les cookies tiers sont encore plus rares, les identifiants universels s’approchent de leur plafond du consentement. Les identifiants probabilistes risquent de perdre un peu en volume si les navigateurs s’y attaquent.
- Au final, un arc précision-volume dessine le Graal inatteignable, que les différentes technologies approchent, sans jamais l’atteindre.
J’écrivais en début d’article que je ne prends aucun risque avec cette vision prospective. C’est simplement qu’une prospective qui est déjà réalité n’est pas vraiment une prospective. Chez Implcit, nous faisons en effet de l’hybridation depuis toujours.
Au cours des prochaines semaines je vais développer comment on hybride déjà data et données :
- en amont d’une campagne
- en cours de campagne
- en bilan de campagne
L’hybridation entre les data déterministes et les données statistiques permet de résoudre la conjecture de la précision et du volume. Et ce, dès aujourd’hui !





