Paris, le 24 mars 2026 – Dans un paysage publicitaire toujours plus fragmenté, Implcit annonce aujourd’hui l’évolution de son positionnement. La startup entend désormais s’imposer comme l’acteur qui réconcilie la stratégie marketing des marques avec la réalité de leurs activations publicitaires digitales, en permettant enfin de relier stratégie, ciblage, exposition média et performance.
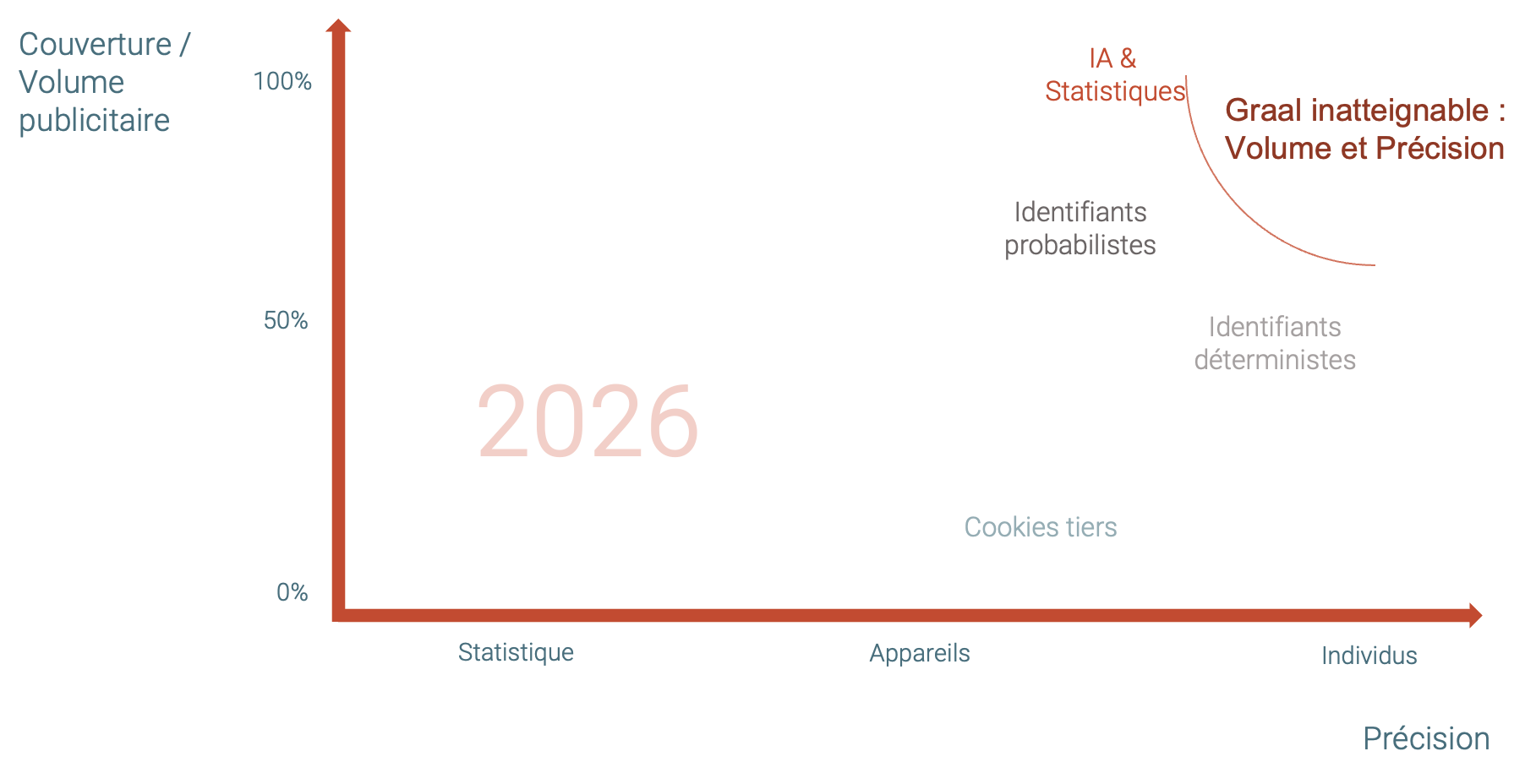
Les stratégies marketing pâtissent de la fragmentation des activations média digitales Au cours des dernières années, les outils d’activation média se sont multipliés. Programmatique, social media, vidéo, CTV, retail media : les dispositifs se diversifient et les indicateurs se multiplient. Mais cette sophistication s’accompagne d’un paradoxe.
Alors que les directions marketing définissent des stratégies marketing de plus en plus fines (personas, attitudes, intentions, moments de vie…) les activations publicitaires digitales s’opèrent souvent dans des environnements technologiques qui parlent une langue différente. Les études statistiques des marques sont rarement compatibles avec les data propriétaires des plateformes publicitaires.
Résultat : les marques disposent de nombreuses capacités de ciblage, mais peinent à répondre à une question pourtant essentielle : comment leurs activations média peuvent-elles toucher réellement les individus qu’elles ont choisi de cibler ?
C’est pour répondre à ce défi qu’Implcit s’impose comme le lien entre la stratégie marketing et l’activation digitale.
“Réconcilier stratégie marketing et activation publicitaire”
Implcit ambitionne de devenir le chaînon manquant entre la réflexion stratégique des marques et la réalité de leurs activations digitales : l’adtech connecte les données de stratégie marketing (profils, intentions, attitudes, comportements online et offline) avec les différentes plateformes publicitaires.
Cette approche permet aux équipes marketing et média de répondre à plusieurs questions clés : Quels sont les supports publicitaires les mieux adaptés à la stratégie des marques ? Comment garantir que les publicités sont bien diffusées sur les personas marketing ? Comment apporter une cohérence entre les différents supports publicitaires sélectionnés ? Quels enseignements peuvent servir à mesurer la pertinence d’une stratégie média ?
Une technologie conçue pour reconnecter les décisions
Concrètement, Implcit crée les personas des marques, selon les critères exacts qui leurs sont propres. Ceci est rendu possible par l’intégration des données d’études de référence (TGI de Kantar Média, et le panel Internet de Médiamétrie).
A l’autre bout de la chaîne, Implcit a créé des connexions avec la plupart des plateformes publicitaires digitales (social, CTV, video, web…). Ainsi, chaque activation publicitaire est réalisée sur-mesure pour chaque persona et chaque plateforme. La traduction des personas en critères de ciblages est réalisée grâce à un savant équilibre d’Intelligence Artificielle pour la puissance et de statistiques pour la fiabilité.
En reconnectant ces deux univers, Implcit entend redonner aux directions marketing et média une vision claire et opérationnelle de leurs activations, afin de piloter les campagnes à partir de la stratégie, et non l’inverse.
« Depuis plusieurs années, les marques ont énormément investi dans les outils d’activation et de mesure. Mais ces outils restent souvent cloisonnés et éloignés de la stratégie marketing définie en amont.
Notre conviction est simple : une stratégie marketing ne vaut que si elle peut réellement être exécutée. Implcit permet précisément de vérifier cet alignement, en reliant les cibles
stratégiques des marques aux individus réellement exposés aux campagnes digitales. Notre ambition est de redonner de la cohérence et de la lisibilité aux décisions média stratégiques. »Laurent Nicolas,
Co-fondateur et CEO